TL;DR: Nebius Token Factory speaks OpenAI’s API protocol. So instead of building a custom Rig provider from scratch, I just pointed
openai::CompletionsClientat their base URL. It took 10 lines of code and one infuriating trailing slash to get working. But I still want to write a proper Rig provider PR.
Not so long ago, I’ve built a little agent (blog post pending) setup that parses the r/kiroIDE subreddit every morning and tells me the latest tea! It stores that data in my Obsidian vault as well as sends me a text message via Telegram. Amazing! When I built it initially I used the Anthropic API, so last night I’ve added support for more endpoints: OpenAI, OpenRouter, and you know what… Let’s add Nebius’ token factory. How hard could that be? Nebius after all uses the OpenAI API framework for invoking LLMs!
Oh and this agent is powered by the rig crate. A very neat and Rusty way to get your agents in line. I will get to how it all works in some future post.
Here’s the thing: Rig, the Rust framework I use for the LLM bits, has native providers for Anthropic, OpenAI, OpenRouter, Gemini, and like 15 others. Nebius isn’t one of them 💔. But Nebius, as I mentioned, exposes an OpenAI-compatible API. Same endpoints, same request format, same response shape. Just one thing to change, the base_url.
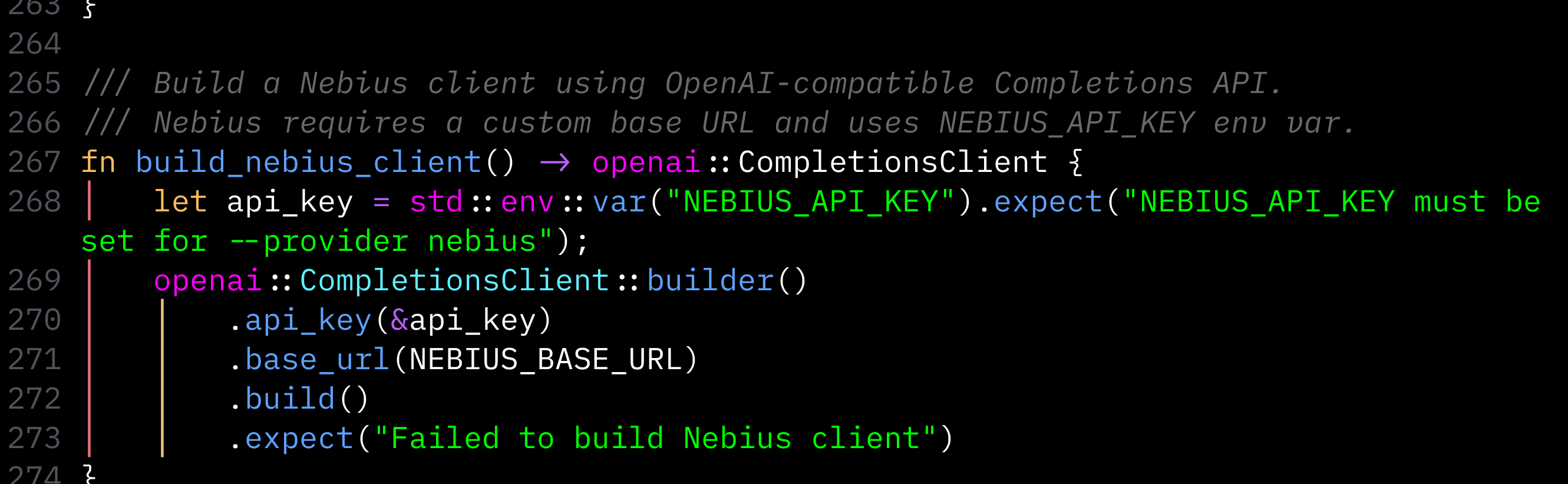
So I was lazy and I didn’t write a custom Rig provider. I just reused openai::CompletionsClient with a custom base URL:
// Set base url
const NEBIUS_BASE_URL: &str = "https://api.tokenfactory.us-central1.nebius.com/v1";
// [...]
fn build_nebius_client() -> openai::CompletionsClient {
// Get stuff from env
let api_key = std::env::var("NEBIUS_API_KEY")
.expect("NEBIUS_API_KEY must be set");
// Make that call
openai::CompletionsClient::builder()
.api_key(&api_key)
.base_url(NEBIUS_BASE_URL)
.build()
.expect("Failed to build Nebius client")
}That’s it. The entire Nebius “provider” is 10 lines of code. No custom traits, no provider extensions, no boilerplate. You can leave now 👋
My agent uses an enum to wrap different provider types:
enum Agent {
Anthropic(rig::agent::Agent<anthropic::completion::CompletionModel>),
Nebius(rig::agent::Agent<openai::completion::CompletionModel>), // Not really OpenAI
Openai(rig::agent::Agent<openai::completion::CompletionModel>),
Openrouter(rig::agent::Agent<openrouter::completion::CompletionModel>),
}Notice something? Nebius and OpenAI share the same CompletionModel type. Because Nebius speaks the same API protocol, Rig can’t tell the difference. It’s just HTTP requests to a different hostname.
This is both beautiful and slightly wrong. Beautiful because it ✨ Just Works ✨. Wrong because… well, Nebius isn’t OpenAI. They have their own model listing format, their own pricing, their own features like dedicated endpoints. Am I to just ignore all that? No! Ideally I would make a PR over to Rig to add support for Token Factory.
I deployed it, sent a test message to my Telegram bot, and got back:
❌ Error: 404 Not FoundOh crap… Wait, what? The API key works. The base URL is correct. The model ID is valid. Why the 404 my sweet API?
I stared at the code for 10 minutes before I saw it:
const NEBIUS_BASE_URL: &str = "https://api.tokenfactory.us-central1.nebius.com/v1/";
// ^^^^ THIS SLASHNote: The first bit of code in this blog post is the working one, as you may note that one does NOT have a trailing slash.
Rig’s post("/chat/completions") appends to that base URL, producing .../v1//chat/completions. Double slash. Nebius says “nah, sorry, don’t know that endpoint.” Removed the trailing slash. Deployed again. Worked instantly.
Nebius hosts a bunch of models, and I wanted to use Kimi-K2.5 until I get Kimi-K2.6. Now, since I already have the base_url, maybe I can get models they have? Maybe even the exact model ID format. Is it kimi-k2.5? moonshot/kimi-k2.5? moonshotai/Kimi-K2.5?
Instead of guessing, let me just curl it:
curl -s "https://api.tokenfactory.us-central1.nebius.com/v1/models" \
-H "Authorization: Bearer $NEBIUS_API_KEY" | jqThis gets me a wonderful list (which is current as of 2026-04-21):
{
"object": "list",
"data": [
{
"id": "deepseek-ai/DeepSeek-V3.2",
"created": 1776811207,
"object": "model",
"owned_by": "system"
},
{
"id": "nvidia/nemotron-3-super-120b-a12b",
"created": 1776811207,
"object": "model",
"owned_by": "system"
},
{
"id": "zai-org/GLM-5",
"created": 1776811204,
"object": "model",
"owned_by": "system"
},
{
"id": "Qwen/Qwen3.5-397B-A17B",
"created": 1776811207,
"object": "model",
"owned_by": "system"
},
{
"id": "moonshotai/Kimi-K2.5",
"created": 1776811205,
"object": "model",
"owned_by": "system"
},
{
"id": "MiniMaxAI/MiniMax-M2.5",
"created": 1776811203,
"object": "model",
"owned_by": "system"
},
{
"id": "deepseek-ai/DeepSeek-V3.2-fast",
"created": 1776811206,
"object": "model",
"owned_by": "system"
},
{
"id": "openai/gpt-oss-120b-fast",
"created": 1776811206,
"object": "model",
"owned_by": "system"
},
{
"id": "MiniMaxAI/MiniMax-M2.5-fast",
"created": 1776811208,
"object": "model",
"owned_by": "system"
},
{
"id": "Qwen/Qwen3-235B-A22B-Thinking-2507-fast",
"created": 1776811203,
"object": "model",
"owned_by": "system"
},
{
"id": "Qwen/Qwen3.5-397B-A17B-fast",
"created": 1776811203,
"object": "model",
"owned_by": "system"
},
{
"id": "Qwen/Qwen3-Next-80B-A3B-Thinking-fast",
"created": 1776811206,
"object": "model",
"owned_by": "system"
},
{
"id": "moonshotai/Kimi-K2.5-fast",
"created": 1776811206,
"object": "model",
"owned_by": "system"
}
]
}So for my case the ID is moonshotai/Kimi-K2.5. Plugged it in, worked first try.
Look, the OpenAI compatibility hack works. It’s 10 lines. It’s zero maintenance. But it’s still a hack. In the future they way Rig does stuff may change, and there may be some certain changes in both Nebius and there that can impact it. So, here’s what a proper Rig provider would give me/us:
Native model constants - Instead of hardcoding "moonshotai/Kimi-K2.5" as a string, we’d have nebius::KIMI_K2_5 or similar. Gotta love that type safety
Proper model listing - Rig providers implement ModelListing which lets you query available models through the framework.
Nebius-specific features - Things like dedicated endpoints (reserved GPU capacity), fine-tuning jobs, could be first-class citizens instead of string parameters.
Cleaner architecture - The enum dispatch would have Nebius(rig::agent::Agent<nebius::completion::CompletionModel>) instead of piggybacking on OpenAI’s type. Semantically correct.
Provider-specific auth - Nebius uses project-based API keys with a specific format. A native provider could handle this more elegantly than std::env::var("NEBIUS_API_KEY").
So yeah, I want to write that PR, soon 🤞 The hack is fine for now, but the proper thing is… well, proper.
I think OpenAI-compatible APIs are one of the most underrated developments in the LLM space right now. They let you:
Rig’s design accidentally makes this even better. Because it separates the HTTP client from the provider logic, any OpenAI-compatible endpoint Just Works with a base_url override. I wonder what other providers use this API compatibility.
But here’s the tension: compatibility is great for adoption, however native providers are better for developer ergonomics. The OpenAI hack gets you running in 10 minutes. The native provider gets you type safety, discoverability, and feature completeness.
Both have their place. I’m just glad we can choose.
Write that proper Rig provider PR (seriously, I should)
If you’re building with Rust and Rig, and you come across an OpenAI-compatible provider, don’t overthink it. Just set the base URL and go. But if you stick with that provider… maybe write the native integration too. Future You will thank present you. (and so will I)
More detail on the Obsidian bit and the agent itself can be found in this blog post. The code is in not yet available, as it’s just a mess, please bear with me. And if you want to see the AWS SDK for Rust pushed to its limits, check out Download and deserialize 10,000 files in 9 seconds.
Until next time friends! Don’t forget to tip your compiler! 🦀